The coding AI, built and proven in the open.
No black box. Every rule is human-readable and versioned — no model fine-tuning. Accuracy is measured against what coders actually billed, and every improvement is proposed, reviewed, and approved by people.
You can't bill what you can't defend — or improve what you can't measure.
“Trust our AI” isn't good enough in coding. The logic has to be inspectable, the accuracy provable, and the changes governed.
Logic you can't audit or explain
A model nobody can open can't answer “why this code?” at appeal — and can't be trusted to bill in your name.
No proof, no version control
No way to prove accuracy, catch a regression before it ships, or track the logic that picks codes as it changes.
A measured loop: run, score, iterate, apply.
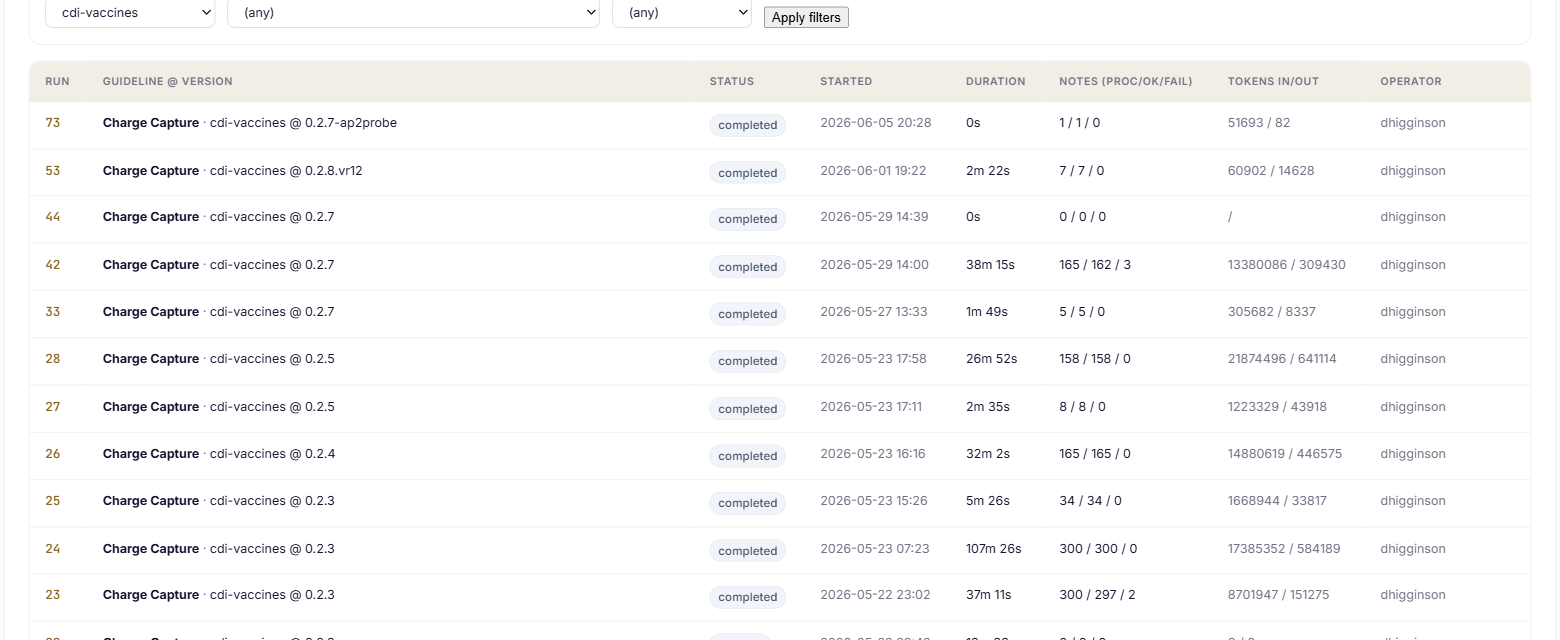
Run cohorts against a guideline version, score them against what coders billed, find the recurring misses, and apply approved fixes — every stage instrumented.
Run
Run a locked cohort of real visits against the current guideline version.
Score
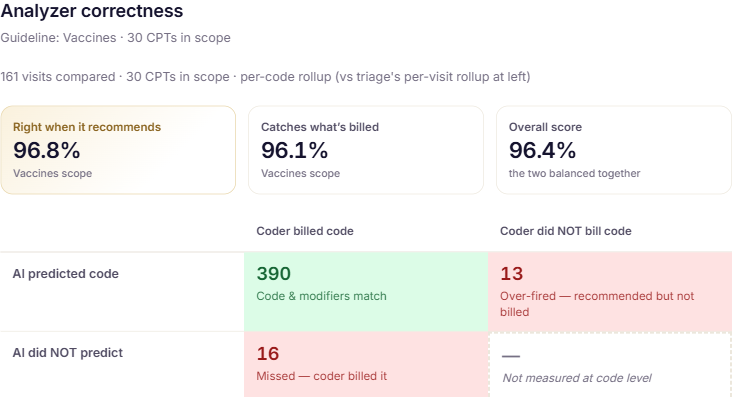
Compare Capsa's codes to what coders billed — precision and recall on the codes that matter.
Iterate
Find the recurring miss patterns and propose rule fixes from real disagreements.
Apply
A reviewer approves the change; it lands as a versioned diff.
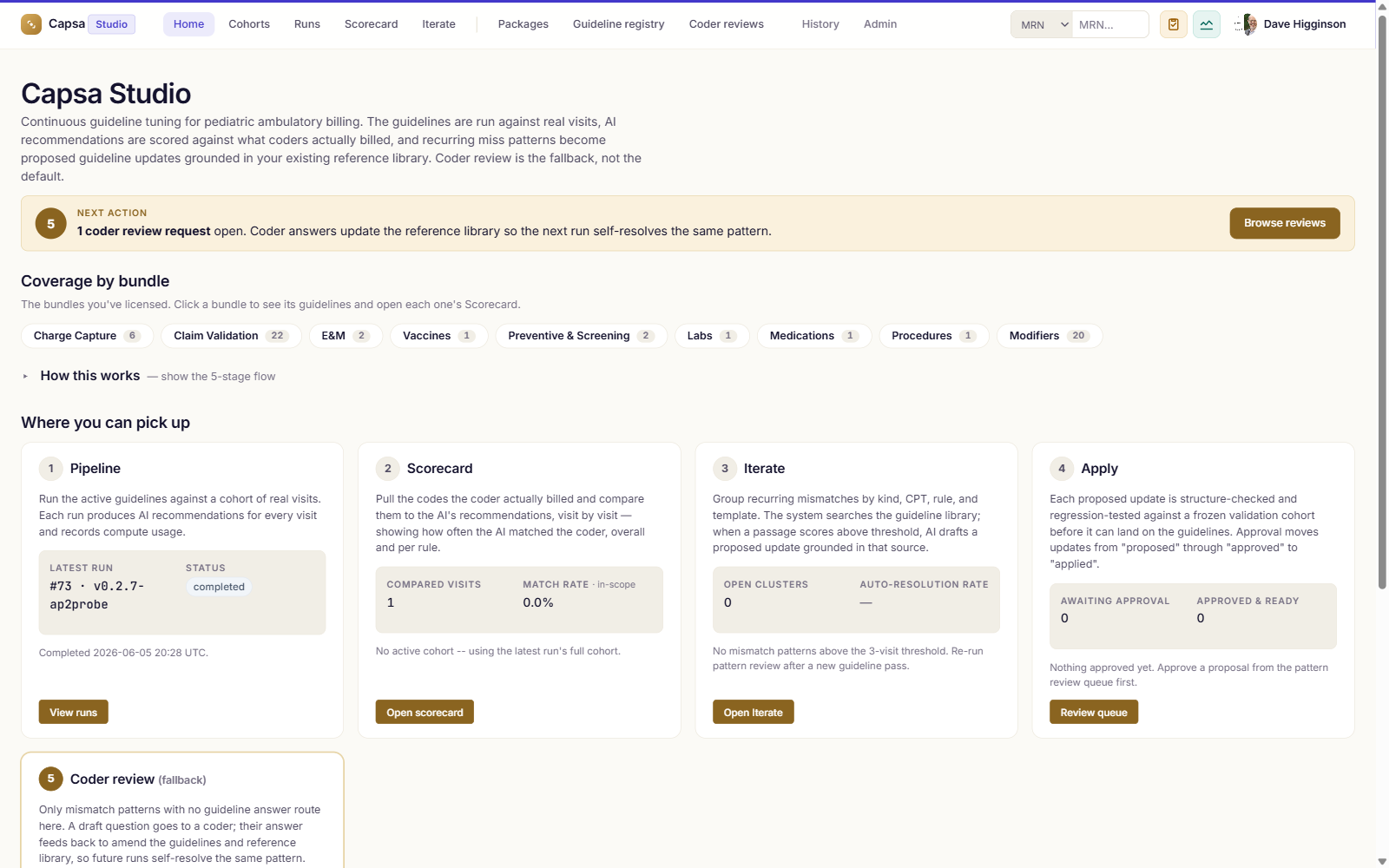
Test on the same visits, every time.
Build cohorts of real, de-identified visits and lock them so results are comparable across versions — then run any cohort against any guideline version and track improvements or regressions.
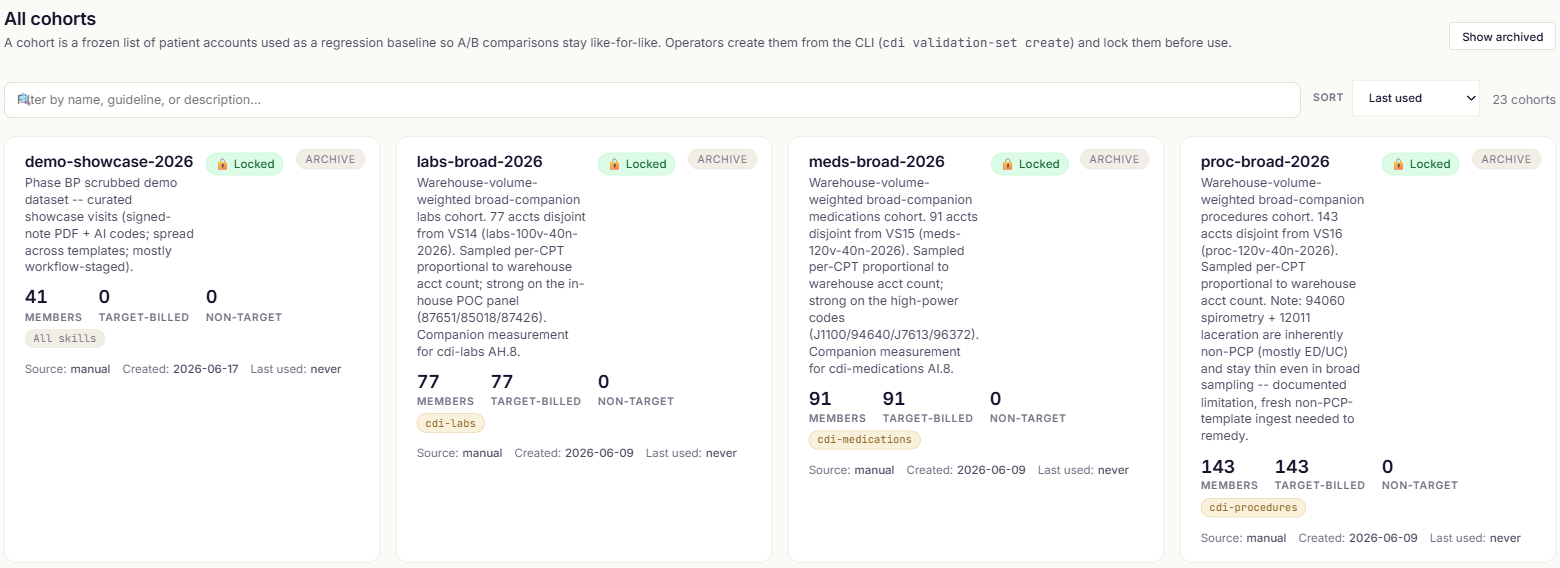
Proof, not vibes.
Scored against the codes your coders actually billed, on two axes — did Capsa triage the visit right, and code it right — with per-CPT and per-rule breakdowns. Then drill from any number to the exact chart words behind a code.
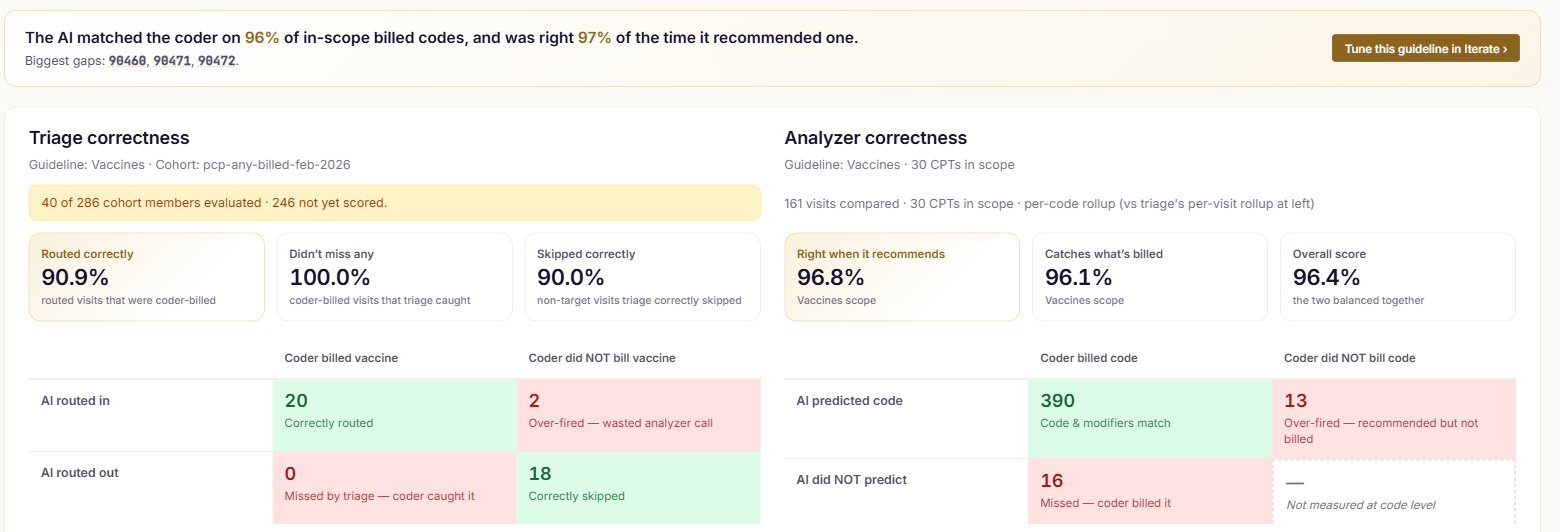

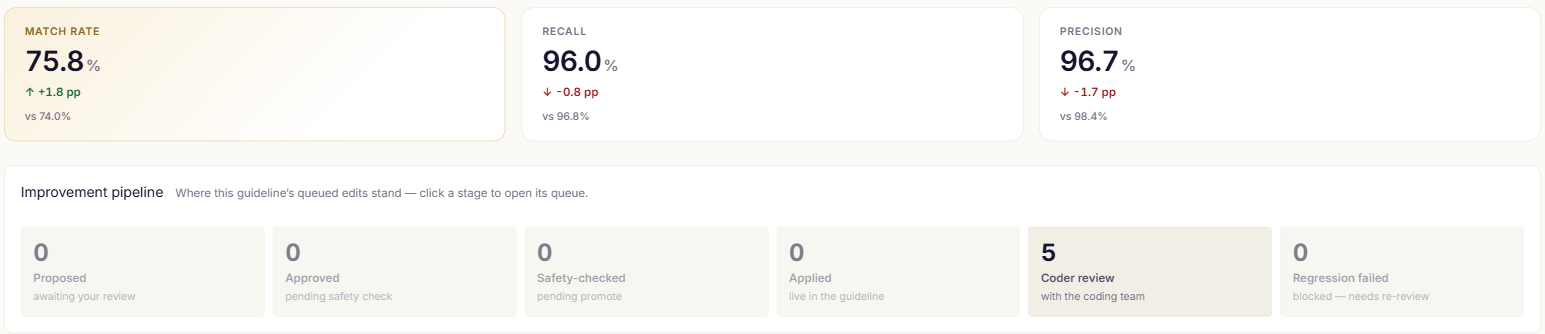
The system tells you where it's weak — people approve the fix.
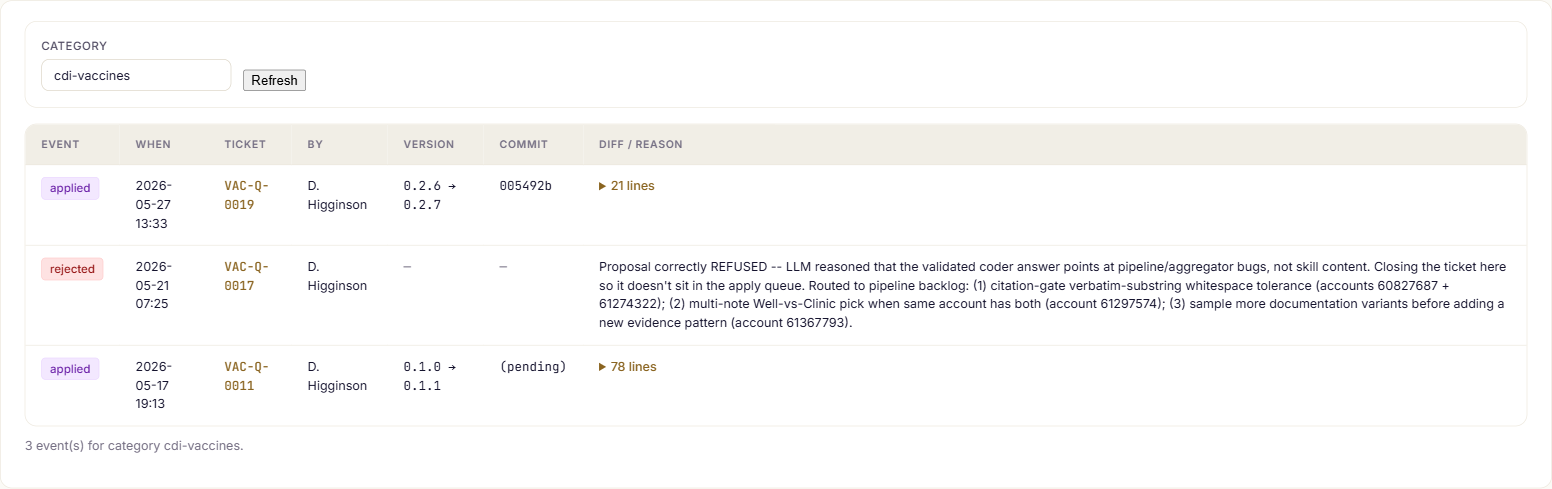
Compare a run to its baseline, review the recurring miss patterns, and apply approved rule edits — versioned like code, with the reviewer's reason on the record.

Glass box, end to end.
Human-readable rules
All logic is explicit rule sets your team can open, read, and change — no opaque model weights, no fine-tuning.
Unsupported codes are dropped
Every quote is checked word-for-word against the chart; if the words aren't there, the code never makes it into the set.
Reproducible by version
Every code is reproducible from the exact guideline version that ran plus its evidence — nothing hidden, nothing un-auditable.
a new coding category, from cold start to matured — on the same framework that proved vaccines (96.9% / 95.5% vs billed).
“New categories inherit the machinery instead of starting over.”
Internal, validated results across two live coding categories (vaccines and health screening), measured on cases your team already coded. Not an external certification.
Studio builds the guidelines the other two run.
The same Capsa engine powers the coder's cockpit and the control tower that oversees the whole pipeline.
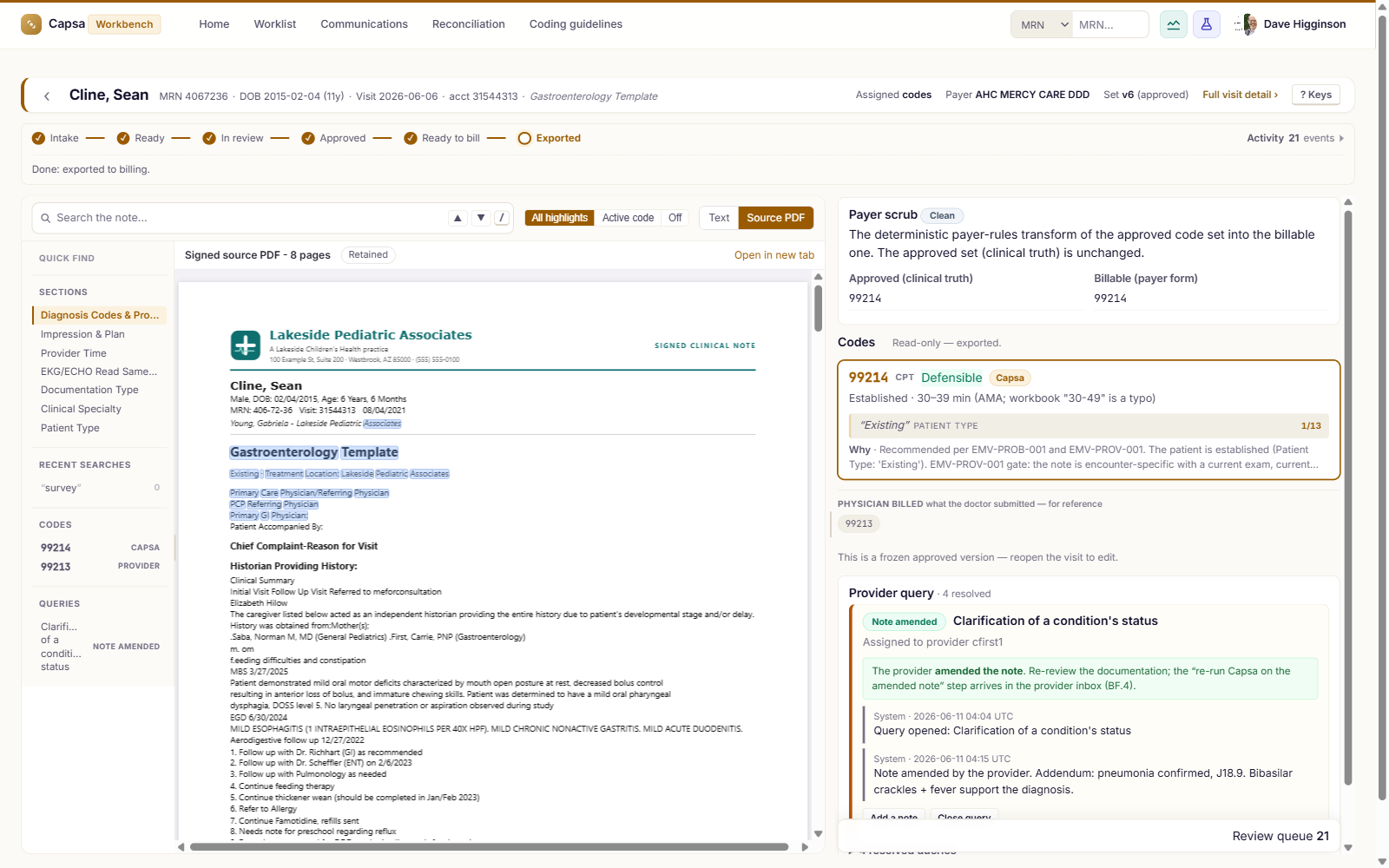
Where coders finalize
Every code cited to the chart, the provider a click away, the claim finalized in one place.
Explore Workbench →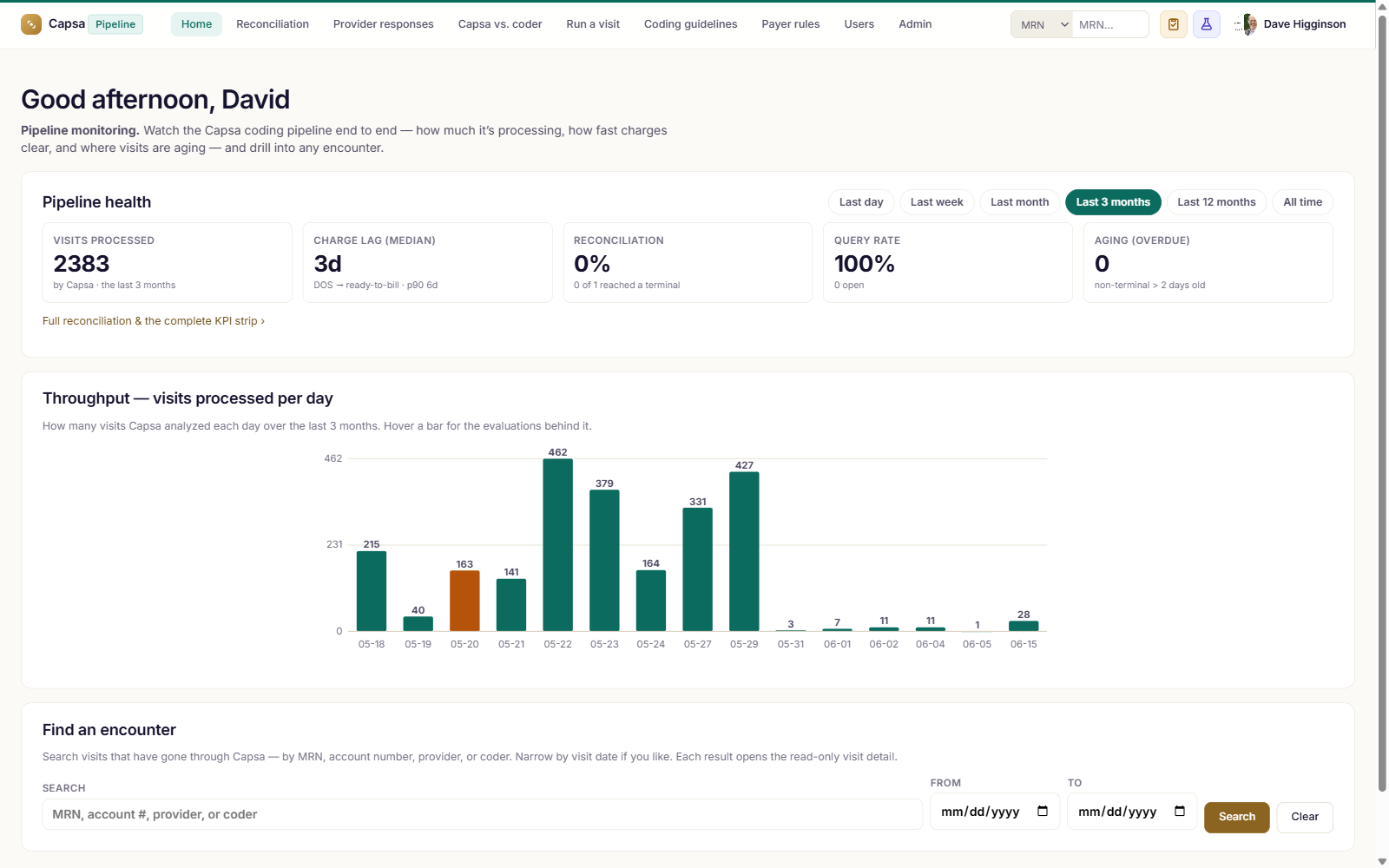
Oversee the whole lifecycle
Throughput, billing lags, bottlenecks, and the charges Capsa captures — for revenue-cycle leaders.
Explore Pipeline →See how we prove every code.
Tell us about your team and we'll walk you through the loop on real cohorts — the scorecard, the evidence trail, and the human-approved improvement cycle.
- Real precision & recall vs billed claims
- Every code traced to verbatim chart text
- Versioned guidelines, full audit trail
- No fine-tuning, no black box
Get in touch
We'll get back to you within one business day.